動作学習研究チーム
研究概要
最近、スマートスピーカーなど人の話す言葉を理解する機械が増えてきていますが、実際の会話では、言葉だけでなく、手の動きや視線なども使って相手とやりとりをしています。このような会話の「インタラクション」を深く理解し、より自然なやりとりができる技術を目指して、私たちのチームでは様々な研究を進めています。
例えば、会話がスムーズに進むためには、言葉のタイミングやテンポが大切です。私たちは、こうした会話の「タイミングのズレ」を活かした特徴を見つけ出し、会話の質を分析する手法を開発しています。また、この研究を通して、コンピュータで操作できるアバターが、より自然に人と会話できるような動きを学べるモデルも作っています。
具体的には、次のようなテーマで研究に取り組んでいます:
- インタラクションの特徴分析: どのようなやり取りが、自然でスムーズな会話につながるのか。
- 会話生成モデルの開発: CGアバターが、人と自然な対話をできるように動作を生成する技術の開発。
- 研究分野
-
- ヒューマンロボットインタラクション
- 機械学習
- キーワード
-
- 強化学習
- ヒューマンロボットインタラクション
- コミュニケーションロボット
- 動作生成
- 内発的動機
- 研究テーマ
-
- 人間とのインタラクション動作の強化学習
- 心理評価に基づく人間らしく自然な動作の生成
- 対話的なロボット操作機構の研究
- 日常活動型の自律ロボット
中村 泰

略歴
- 2004年
- 奈良先端科学技術大学院大学
- 2006年
- 大阪大学大学院工学研究科
- 2020年
- 理化学研究所
メンバー
- 中村 泰
- チームディレクター
- Huthaifa Ahmad
- 研究員
- Liliana Villamar Gomez
- 特別研究員
- 岡留 有哉
- 客員研究員
- Chenfei Xu
- 大学院生リサーチ・アソシエイト兼研修生
- Zhichao Chen
- 研修生
- Xuhai Li
- 研修生
- 阿部 哲也
- 研修生
- 中村 陽
- 研修生
過去のメンバー
- 西村 優佑
- 研究パートタイマーI兼研修生(2021/01-2023/03)
- Yazan Alkatshah
- 研究パートタイマーI兼研修生(2023/05-2025/3)
- Siyu Wang
- 研究パートタイマーⅠ(2025/04-2026/03)
- 髙城 頌太
- 事務パートタイマーII(2021/12-2022/03)
- Duong Nam Tran
- 研修生(2024/8-2024/09)
- Haoyang Jiang
- 研修生(2024/06-2025/3)
- Bang Trong Nguyen
- 研修生(2024/07-2025/3)
- Zicheng Zhao
- 研修生(2024/09-2026/03)
- 柴﨑 誉広
- 研修生(2025/07-2026/03)
- 服部 祐音
- 研修生(2025/07-2026/03)
- 新井 那由多
- インターン(2023/09)
- Sara Pia Calvitto
- インターン(2023/08-2023/11)
研究成果
インタラクション動作の逆強化学習
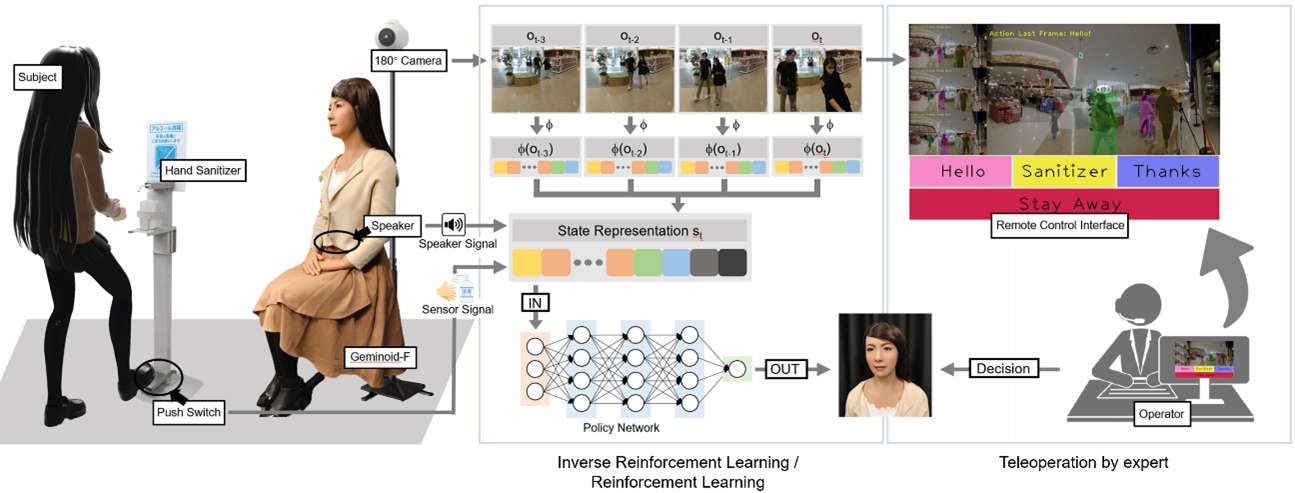
実世界でのヒューマンロボットインタラクション (HRI) においては、ロボットが直面する状態が多様であるため、制御ルールをハンドコーディングで実装することは容易ではありません。このような課題において深層学習を用いた手法が期待されています。我々は深層ニューラルネットワークを用いた逆強化学習を HRI 分野の実課題に応用しました。ここでは、アンドロイドがショッピングモールの受付として来客に手指の消毒をお願いする、という課題に取り組みました。遠隔操作により収集したデータを用いた学習を行うことで、アンドロイドは練習を積んだ人間による遠隔操作に近い効率で来客に消毒の実施を促すことができるようになりました。
主要論文
-
Chenfei Xu, Huthaifa Ahmad, Yuya Okadome, Hiroshi Ishiguro, Yutaka Nakamura
"Action-Inclusive Multi-future Prediction Using a Generative Model in Human-Related Scenes for Mobile Robots"
IEEE Access, 13, pp. 167034 – 167044 (2025) -
Zhichao Chen, Chenfei Xu, Huthaifa Ahmad, Yuya Okadome, Hiroshi Ishiguro, Yutaka Nakamura
"A Feasibility study with in-the-wild data in human interaction settings: Acoustic-visual fusion for predictive sound source positioning"
IEEE Access, 13, pp.150365 – 150378 (2025) -
Huthaifa Ahmad, Yuya Okadome, Yasutomo Kawanishi, Koichiro Yoshino, Takashi Minato, Michihiko Minoh, Yutaka Nakamura
"A Body Design Leveraging Passive Dynamics for Mobile Robots Coexisting With Humans"
IEEE Access, 13, pp. 74887-74899 (2025) -
Toshiki Watanabe, Akihiro Kubo, Kai Tsunoda, Tatsuya Matsuba, Shintaro Akatsuka, Yukihiro Noda, Hiroaki Kioka, Jin Izawa, Shin Ishii, Yutaka Nakamura
"Hierarchical reinforcement learning with central pattern generator for enabling a quadruped robot simulator to walk on a variety of terrains"
Scientific Reports, 15, 11262 (2025) -
Yuya Okadome and Yutaka Nakamura,
"Feature extraction method using lag operation for sub-grouped multidimensional time series data."
IEEE Access, Volume: 12, Page(s): 98945 – 98959(2024) -
Huthaifa Ahmad, Yutaka Nakamura
”A Study on Designing a Robot with Body Features Tailored for Coexistence with Humans in Daily Life Environments."
33rd IEEE International Conference on Robot and Human Interactive Communication (ROMAN)(2024) -
Zhichao Chen, Yutaka Nakamura, Hiroshi Ishiguro,
“Outperformance of Mall-Receptionist Android as Inverse Reinforcement Learning Is Transitioned to Reinforcement Learning,”
IEEE Robotics and Automation Letters. ( open access ) -
岡留 有哉, 阿多 健史郎, 石黒 浩, 中村 泰
”対話中の振る舞い予測のための時間的整合性に注目した自己教師あり学習”
人工知能学会論文誌 (2022) -
Zhichao Chen, Nakamura Yutaka, Hiroshi Ishiguro
"Android As a Receptionist in a Shopping Mall Using Inverse Reinforcement Learning"
IEEE/RSJ International Conference on Intelligent Robots and Systems (2022) -
Naoki Ise, Yoshihiro Nakata, Yutaka Nakamura, Hiroshi Ishiguro
"Gaze motion and subjective workload assessment while performing a task walking hand in hand with a mobile robot"
International Journal of Social Robotics (2022) -
Huthaifa Ahmad, Yutaka Nakamura
"A robot that is always ready for safe physical interactions"
Interdisciplinary Conference on Mechanics, Computers and Electrics (ICMECE 2022) -
Satoshi Yagi, Yoshihiro Nakata, Yutaka Nakamura, Hiroshi Ishiguro
"Can an android's posture and movement discriminate against the ambiguous emotion perceived from its facial expressions?"
Plos ONE (2021) -
Yusuke Nishimura, Yutaka Nakamura, and Hiroshi Ishiguro
"Human interaction behavior modeling using Generative Adversarial Networks"
Neural Networks, 132, pp.521—531 (2020) -
Ahmed Hussain Qureshi, Yutaka Nakamura, Yuichiro Yoshikawa, and Hiroshi Ishiguro
"Intrinsically motivated reinforcement learning for human-robot interaction in the real-world"
Neural Networks, 107, pp. 23—33 (2018) -
Yuya Okadome, Yutaka Nakamura, and Hiroshi Ishiguro
"A confidence-based roadmap using Gaussian process regressio"
Autonomous Robots, 41(4) (2017) -
Yutaka Nakamura, Takeshi Mori, Masa-aki Sato, and Shin Ishii
"Reinforcement learning for a biped robot based on a CPG-actor-critic method"
Neural Networks, 20(6), pp.723-735 (2007)
関連リンク
お問い合わせ先
yutaka.nakamura [at] riken.jp
※[at]は@に置き換えてください。